Ex 7.28 DDCA 2 Ed
O programa abaixo está executando no MIPS com pipeline (com controle de Hazards).
Quais registradores são escritos e quais são lidos no quinto ciclo de clock?

Ex 7.28 DDCA 2 Ed
O programa abaixo está executando no MIPS com pipeline (com controle de Hazards).
Quais registradores são escritos e quais são lidos no quinto ciclo de clock?
Escrito: $s1
Lido: $t0 e $t5
Ex 7.29 DDCA 2 Ed
O programa abaixo está executando no MIPS com pipeline (com controle de Hazards).
Quais registradores são escritos e quais são lidos no quinto ciclo de clock?
Escrito: $s0
Lido: $t4 e $t5
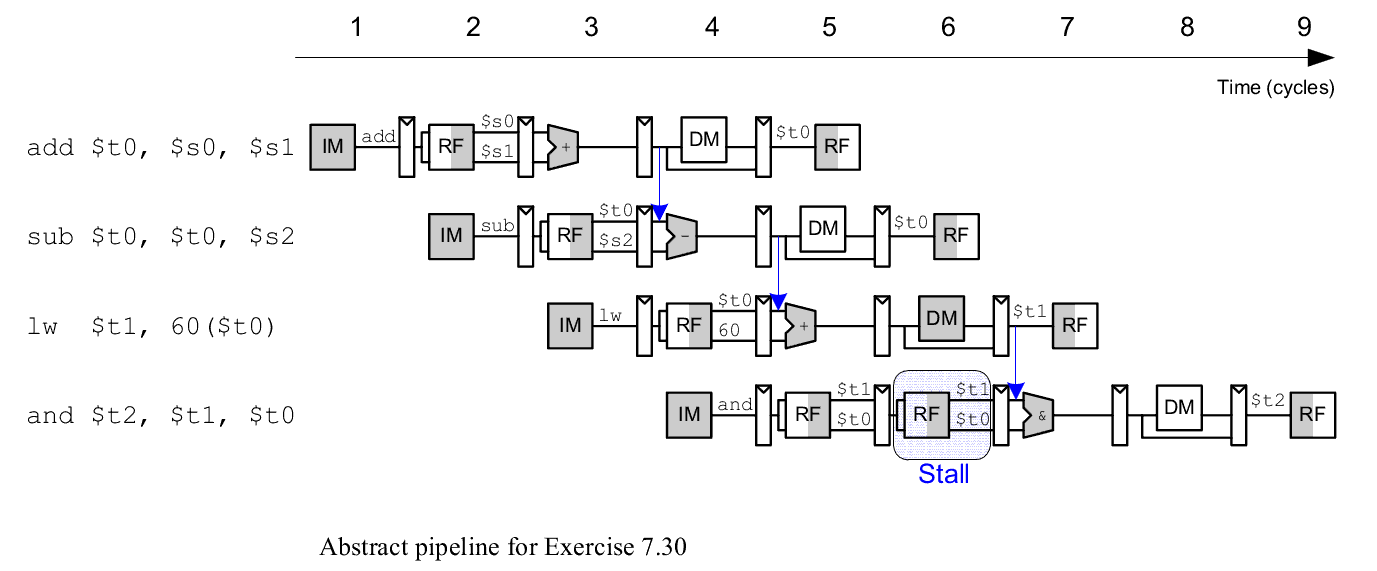
Ex 7.30 DDCA 2 Ed
Mostre as ocorrências de forwarding e stalls, do código abaixo, se executado no MIPS com pipeline.
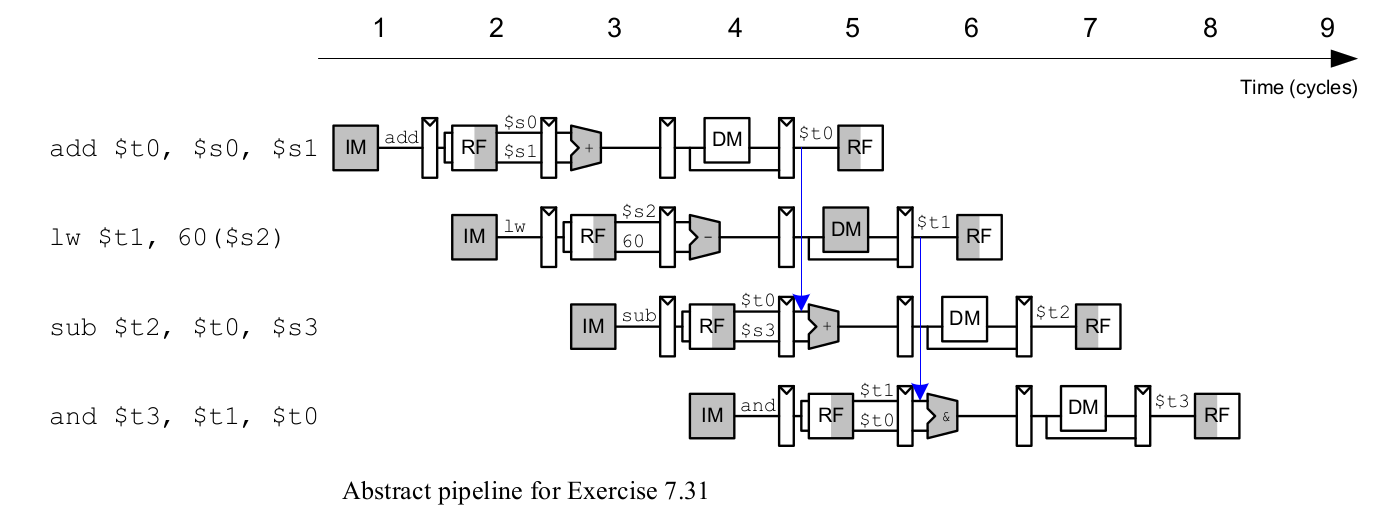
Ex 7.31 DDCA 2 Ed
Mostre as ocorrências de forwarding e stalls, do código abaixo, se executado no MIPS com pipeline.
Ex 7.32 DDCA 2 Ed
Quantos ciclos de “clock” são necessários para que o MIPS, com pipeline, execute todas as instruções do programa abaixo?
Recursos do MIPS: forwarding, execução do BEQ no segundo estágio, stall gerado por hardware.
O código é executado em 23 ciclos de “clock”:
1 (addi) + 5(laços)*4(beq+addi+jump+stall) + 2 (beq+stall) = 23.Ex 7.33 DDCA 2 Ed
Quantos ciclos de “clock” são necessários para que o MIPS com pipeline execute todas as instruções do programa abaixo?
Recursos do MIPS: forwarding, execução do BEQ no segundo estágio, stall gerado por hardware.
Só é necessário adicionar o ciclo de stall depois do Jump e do BEQ.
O código é executado em 66 ciclos de “clock”:
3(add+add+addi) + 6(slt+beq+add+addi+jump+stall)*10(laços) + 3(slt+beq+stall) = 66.Questão 7.1 DDCA 2 Ed – pg 473
Explique as vantagens de um microprocessador com pipeline.
Um microprocessador com pipeline de N estágios, terá um ganho “ideal” de velocidade de N vezes sobre o mesmo microprocessador com execução em um único ciclo.
O ganho não será de N vezes em função de:
A adição de registradores entre os estágios, adiciona o tempo de propagação deles ao tempo total do pipeline.
Não são todas as instruções que utilizam todos os estágios do pipeline. Em função disso, existem ciclos sem trabalho útil em algum estágio do pipeline.
Porém, o custo adicional não é tão grande. Ele envolve alguns registradores (fronteira entre as etapas), MUX para fazer o forwarding e as unidades de controle específicas para o pipeline.
COD 4Ed Ex. 4.20
Para os dois trechos de código abaixo, pede-se:
Mostrar as dependências existentes;
Para um pipeline com 5 estágios, sem forwarding e sem stall, mostre todos os hazards existentes;
Para um pipeline com 5 estágios, com forwarding e sem stall, mostre todos os hazards existentes.
Trecho 1:
Trecho 2:
Solução do item A:
Dependências estão na mesma cor e em negrito:
| add R1, R2, R1 |
| lw R2, 0(R1) |
| lw R1, 4(R1) |
| or R3, R1, R2 |
| lw R1, 0(R1) |
| and R1, R1, R2 |
| lw R2, 0(R1) |
| lw R1, 0(R3) |
Solução do item B:
Pipelilne com 5 estágios, sem forwarding e sem stall:
Solução do item C:
Pipelilne com 5 estágios, com forwarding e sem stall:
| add R1, R2, R1 |
| lw R2, 0(R1) |
| lw R1, 4(R1) |
| or R3, R1, R2 |
| lw R1, 0(R1) |
| and R1, R1, R2 |
| lw R2, 0(R1) |
| lw R1, 0(R3) |
COD 4Ed Ex. 4.21
Para os dois trechos de código abaixo, pede-se:
Insira os NOPs necessários para uma execução correta;
Rearranje as instruções para obter a menor quantidade de NOPs.
Trecho 1:
Trecho 2:
Solução item A:
Trecho 1:
Trecho 2:
Solução item B:
Trecho 1, sem ganho de desempenho:
Trecho 2: não tem como mudar a sequência sem adicionar nops.
Para o trecho de código abaixo, executando no MIPS com pipeline, pergunta-se:
Existe algum tipo de dependência entre as instruções?
Caso sim, essa condição se refere ao tempo de execução ou compilação? (justifique)
Caso não, justifique a sua resposta.
| instrução / clock | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 |
|---|---|---|---|---|---|---|---|---|
| sw $3, 0($2) | IF | ID | EX | MEM | WB | |||
| lw $4, 0($5) | IF | ID | EX | MEM | WB | |||
Não existe dependência.
A dependência que pode gerar problemas é a de leitura depois da escrita (RAW) no banco de registradores.
Neste caso, como a instrução sw faz uma leitura do banco de registradores, mesmo se o lw usasse o mesmo registrador, teríamos uma escrita após leitura (WAR) que não gera hazards.
Variação sobre o Ex 7.33 DDCA 2 Ed
Quantos ciclos de “clock” são necessários para que o MIPS com pipeline execute todas as instruções do programa abaixo?
Recursos do MIPS: forwarding, execução do BEQ no quarto estágio, sem stall gerado por hardware.
Para a execução, somente com bypass, deve-se adicionar os seguintes NOPS para os casos de hazard de controle:
Três NOPS depois do BEQ, para evitar a execução de instruções indevidas na ocorrência do desvio do BEQ;
Um NOP depois do Jump, para evitar a execução de instruções indevidas.
add $s0, $0, $0 # i=0
add $s1, $0, $0 # soma = 0
addi $t0, $0, 10 # $t0 = 10
LOOP:
slt $t1, $s0, $t0 # if (i < 10), $t1 = 1, else $t1 = 0
beq $t1, $0, FIM # if $t1 == 0 (i > = 10), desvia para o FIM
nop
nop
nop
add $s1, $s1, $s0 # soma = soma + i
addi $s0, $s0, 1 # incrementa i
j LOOP
nop
FIM:Solução:
A etapa inicial do código consome:
add+add+addi = 3
A etapa relativa ao laço, que executa 10 vezes, consome:
9(slt+beq+nop+nop+nop+add+addi+jump+nop)*10(laços) = 90
A saída do laço, consome:
slt+beq+nop+nop+nop = 5.
Total (3+90+5) = 98 ciclos de clock.
Variação sobre o Ex 7.33 DDCA 2 Ed
Quantos ciclos de “clock” são necessários para que o MIPS com pipeline execute todas as instruções do programa abaixo?
Recursos do MIPS: sem forwarding, execução do BEQ no quarto estágio, sem stall gerado por hardware.
Para a execução, no Pipeline Simples, deve-se adicionar os seguintes NOPS:
Três NOPS depois do BEQ, para evitar a execução de instruções indevidas na ocorrência do desvio do BEQ;
Um NOP depois do Jump, para evitar a execução de instruções indevidas.
Dois NOPS depois de cada instrução com dependência de dados.
add $s0, $0, $0 # i=0
add $s1, $0, $0 # soma = 0
addi $t0, $0, 10 # $t0 = 10
nop
nop
LOOP:
slt $t1, $s0, $t0 # if (i < 10), $t1 = 1, else $t1 = 0
nop
nop
beq $t1, $0, FIM # if $t1 == 0 (i > = 10), desvia para o FIM
nop
nop
nop
add $s1, $s1, $s0 # soma = soma + i
addi $s0, $s0, 1 # incrementa i
j LOOP
nop
FIM:Solução:
A etapa inicial do código consome:
add+add+addi+nop+nop = 5
A etapa relativa ao laço, que executa 10 vezes, consome:
11(slt+nop+nop+beq+nop+nop+nop+add+addi+jump+nop)*10(laços) = 110
A saída do laço, consome:
slt+nop+nop+beq+nop+nop+nop = 7.
Total (5+110+7) = 122 ciclos de clock.
Variação sobre o Ex 7.33 DDCA 2 Ed
Quantos ciclos de “clock” são necessários para que o MIPS com pipeline execute todas as instruções do programa abaixo?
Recursos do MIPS: sem forwarding, execução do BEQ no quarto estágio, sem stall gerado por hardware.
Para a execução, no Pipeline Simples, deve-se adicionar os seguintes NOPS:
Três NOPS depois do BEQ, para evitar a execução de instruções indevidas na ocorrência do desvio do BEQ;
Um NOP depois do Jump, para evitar a execução de instruções indevidas.
Dois NOPS depois de cada instrução com dependência de dados.
add $s0, $0, $0 # i=0
nop
nop
add $s1, $0, $s0 # soma = 0 dependência em $s0
addi $t0, $0, 10 # $t0 = 10
nop
nop
LOOP:
slt $t1, $s0, $t0 # if (i < 10), $t1 = 1, else $t1 = 0
nop
nop
beq $t1, $0, FIM # if $t1 == 0 (i > = 10), desvia para o FIM
nop
nop
nop
add $s1, $s1, $s0 # soma = soma + i
addi $s0, $s0, 1 # incrementa i
j LOOP
nop
FIM:Solução:
A etapa inicial do código consome:
add+nop+nop+add+addi+nop+nop = 7
A etapa relativa ao laço, que executa 10 vezes, consome:
11(slt+nop+nop+beq+nop+nop+nop+add+addi+jump+nop)*10(laços) = 110
A saída do laço, consome:
slt+nop+nop+beq+nop+nop+nop = 7.
Total (7+110+7) = 124 ciclos de clock.
Considerando o pipeline simples, a instrução JAL, que é do tipo J, e trabalha em conjunto com a instrução JR, em princípio, pode ser executada nos seguintes estágios:
Estágio ID (decodificação);
Estágio EX (execução);
Estágio MEM (leitura/escrita na memória);
Estágio WB (escrita no banco de registradores).
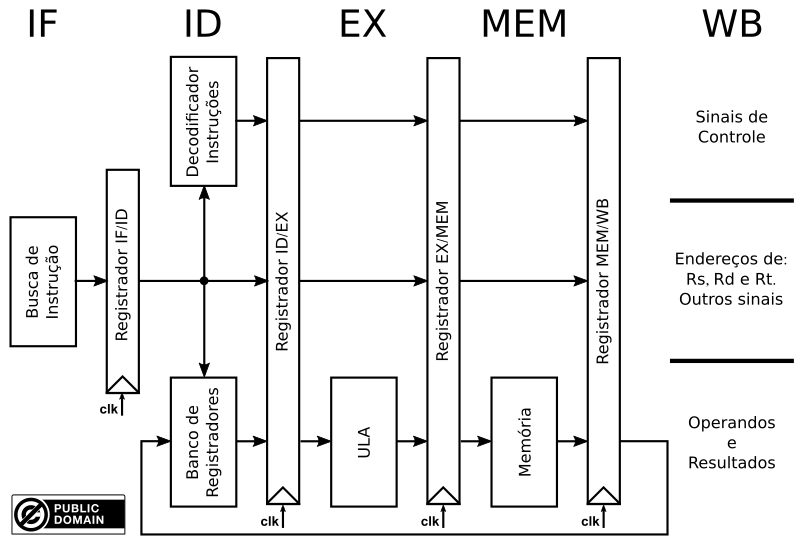
Para esses casos, quais das afirmações mostradas abaixo são corretas?
1 - A execução, do JAL, no estágio ID necessita de duas instruções NOP após o JAL.
2 - A execução, do JAL, no estágio EX necessita de duas instruções NOP após o JAL.
3 - A execução, do JAL, no estágio MEM necessita de três instruções NOP após o JAL.
4 - A execução, do JAL, no estágio WB não necessita de instruções NOP após o JAL.
5 - A instrução JAL não permite a utilização da decisão postergada para evitar os NOPs.
6 - A execução, do JAL, no estágio ID necessita de uma instrução NOP após o JAL e, no mínimo, uma instrução antes do JR de retorno dessa instrução.
7 - A execução, do JAL, no estágio EX não necessita de instruções antes do JR de retorno dessa instrução.
Verdadeiras: 2, 3, 6 e 7.
A instrução JAL chama uma subrotina que utiliza o R31 para fazer o retorno.
Portanto, para que o retorno possa acontecer, no clock da execução do JR, a instrução JAL (que chamou a subrotina) deve estar no estágio WB ou ter saído do pipeline.
O número de NOPs após o JAL é igual ao número da etapa em que ele for executado menos um.
É possível usar a decisão postergada com o JAL.