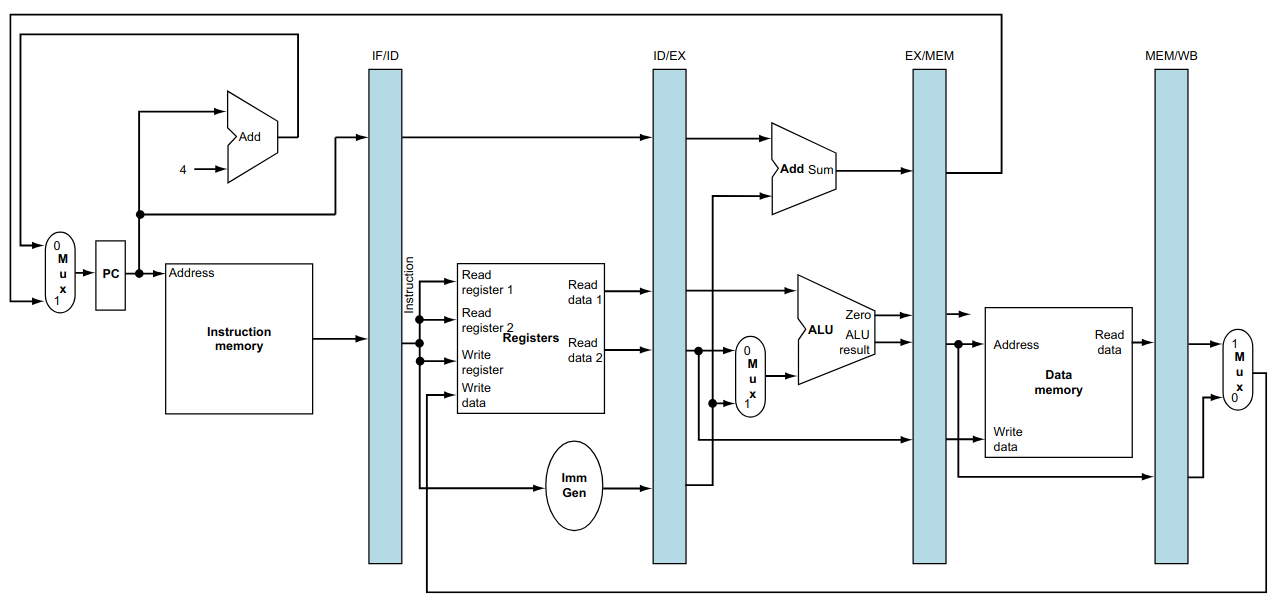
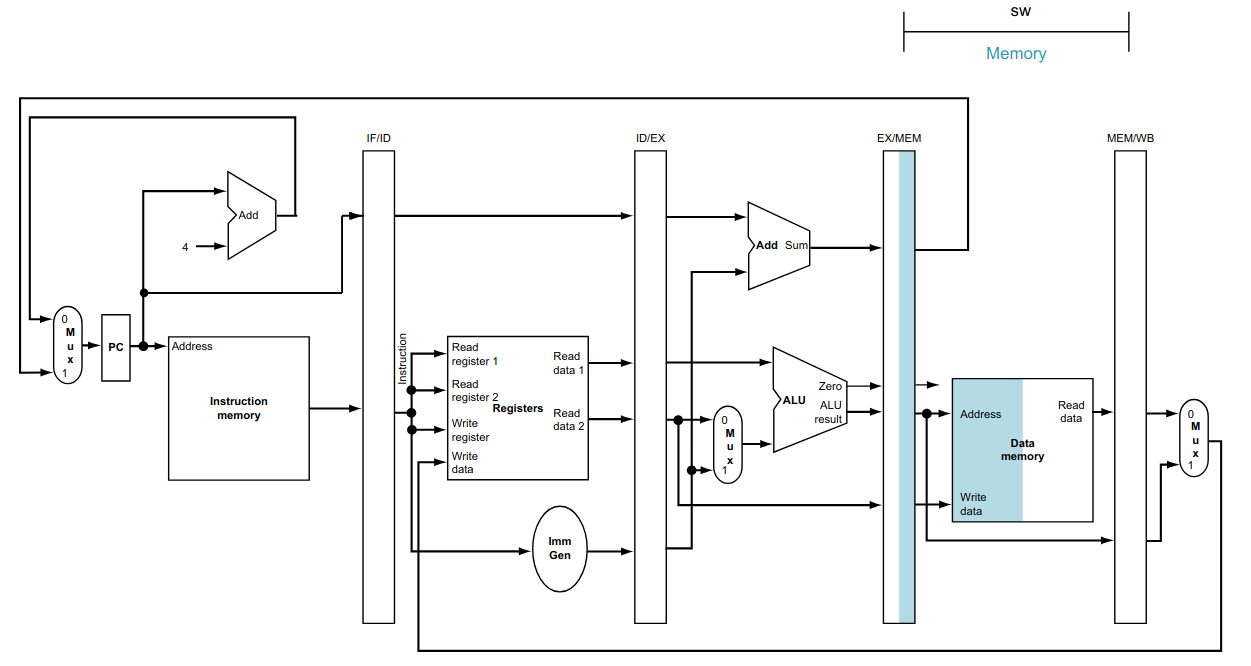
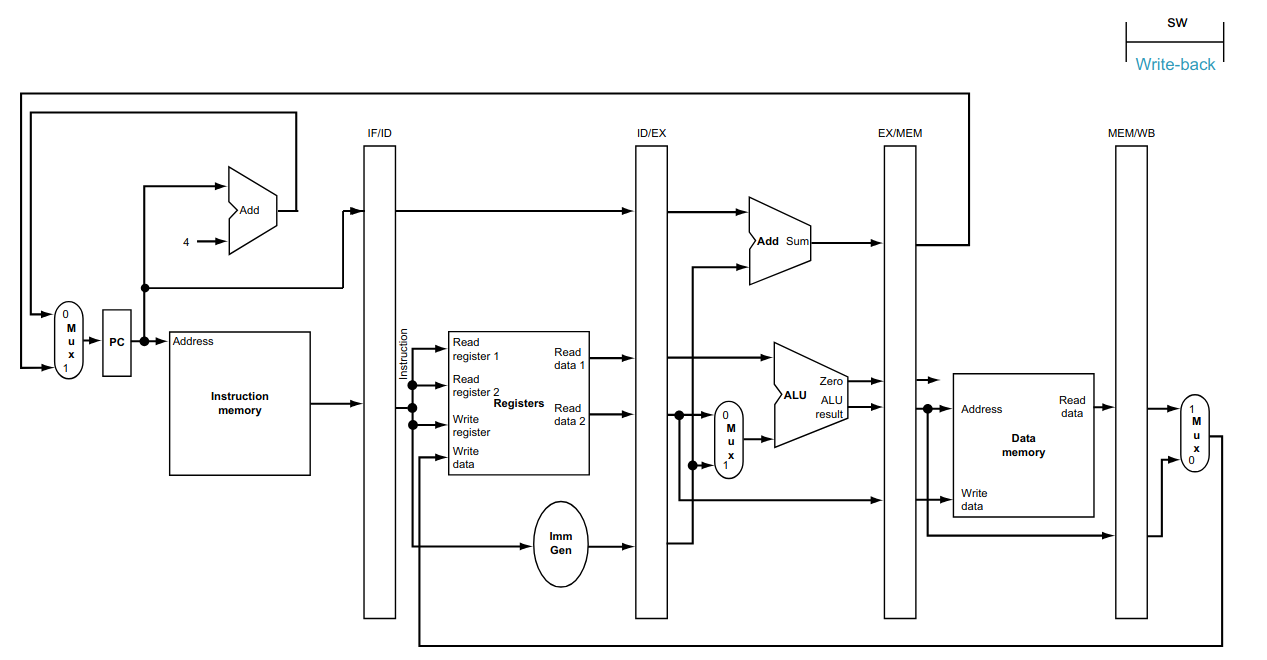
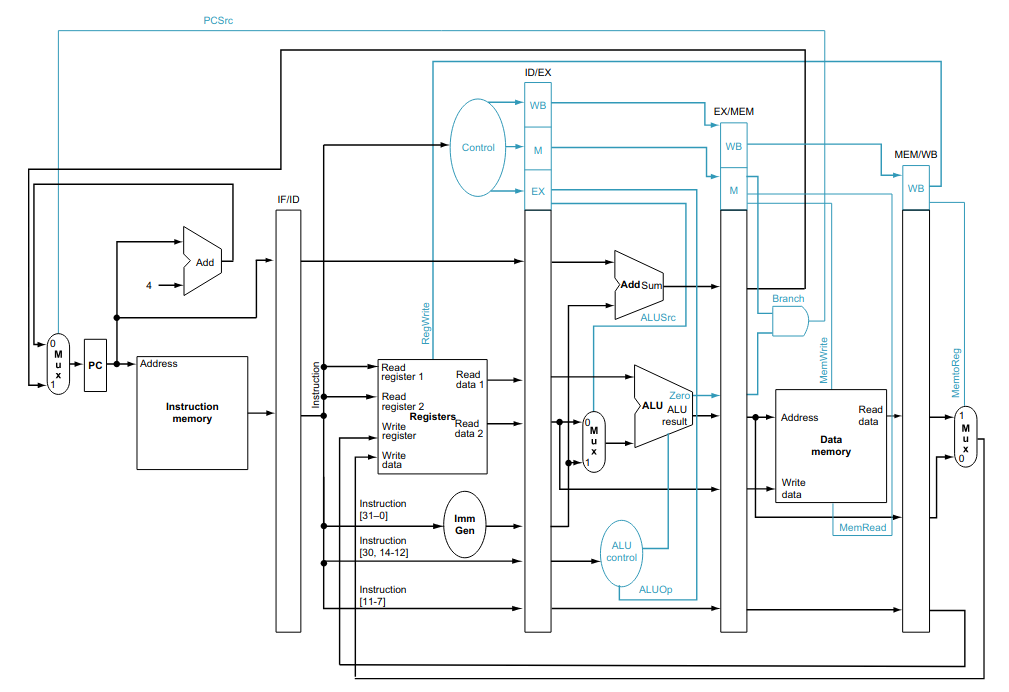
O RISC V estudado até agora, chamado de single cycle (ciclo único), executa cada uma de suas instruções em um único ciclo de clock.
Porém, nem todas as instruções do RISC V precisam do mesmo tempo para serem executadas.
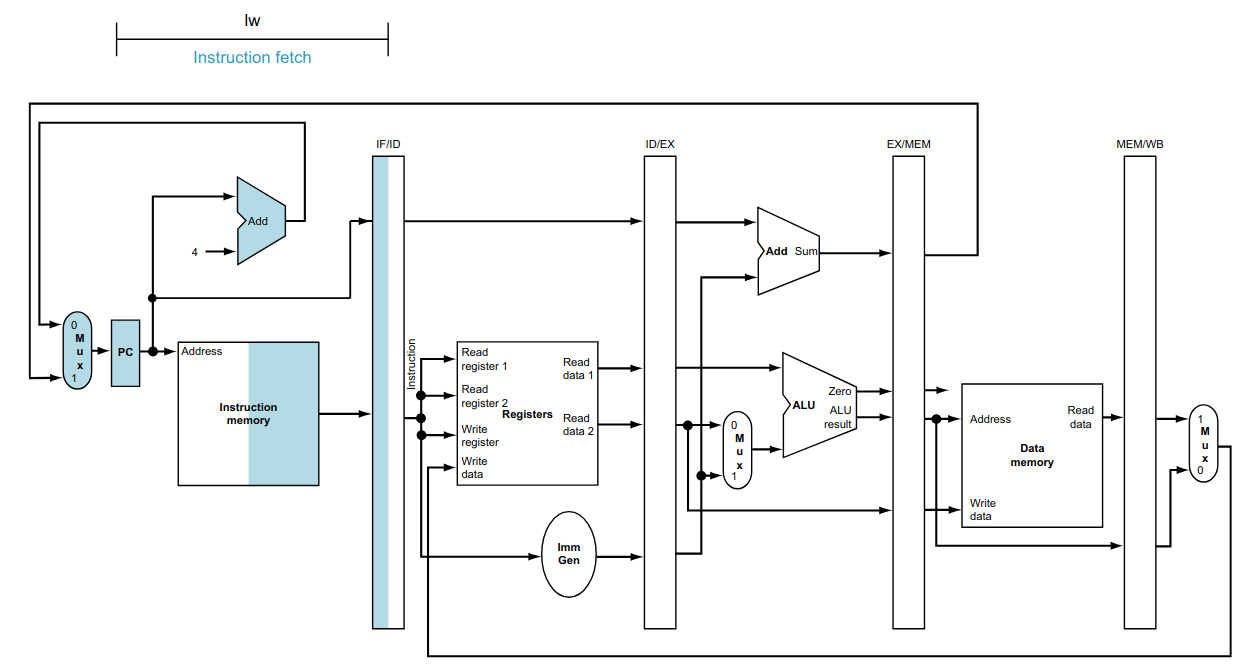
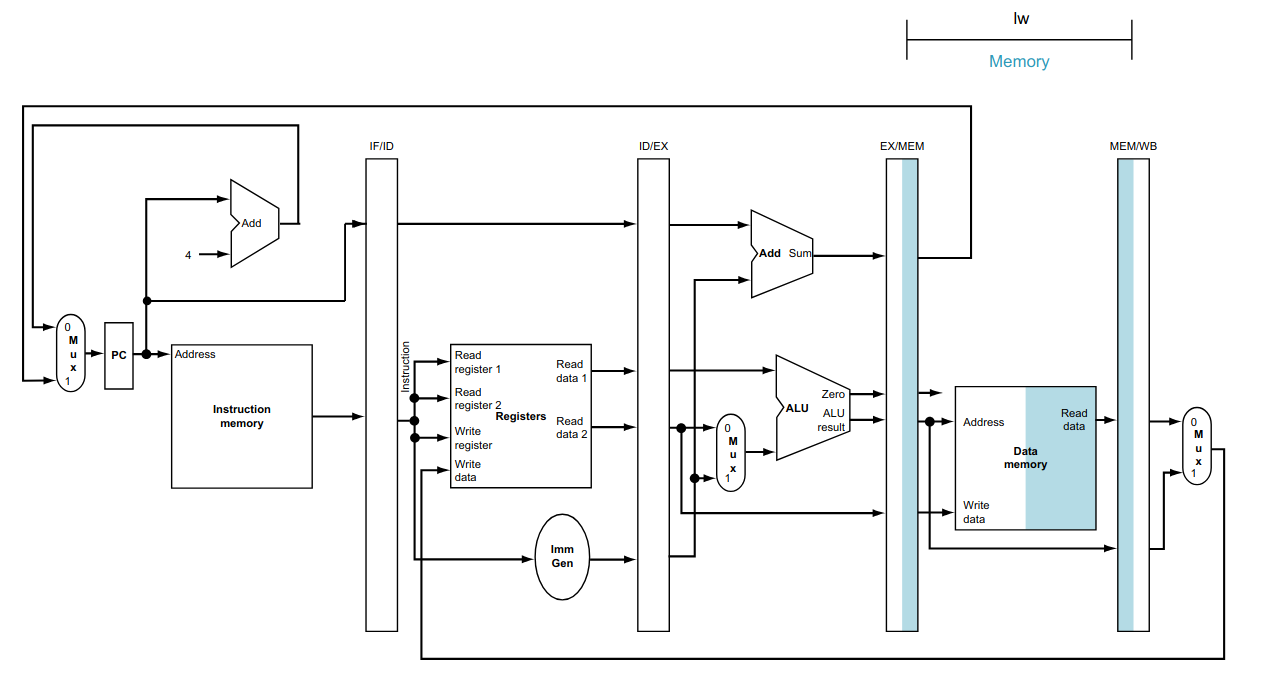
Por exemplo, a instrução lw utiliza todas as etapas do fluxo de dados, como visto abaixo.

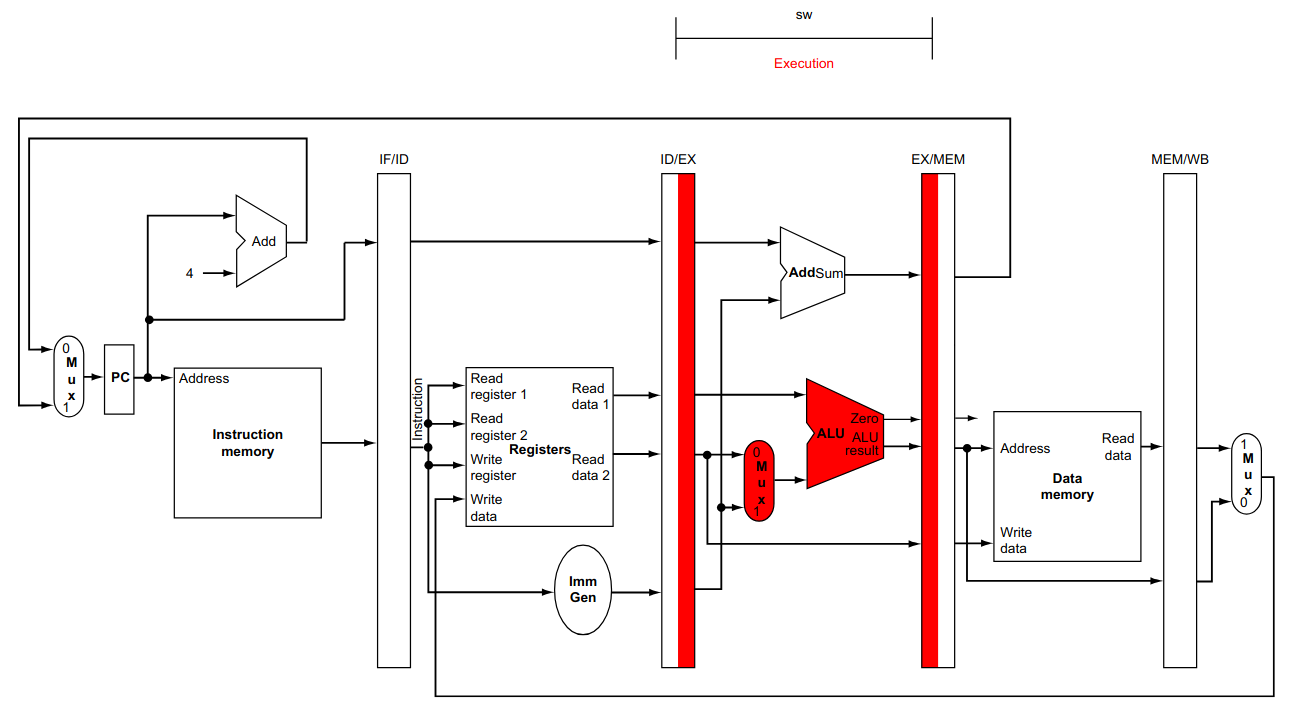
As instruções do tipo R, não utilizam o acesso à memória RAM e o seu tempo de execução é menor que o da instrução lw.

No RISC V de ciclo único, o período do clock deve ser definido pela instrução que demora mais tempo a ser executada, ou seja, a instrução com a maior latência - no caso, a instrução lw.
Isso provoca um disperdício de tempo de processamento nas instruções com menor latência, uma vez que elas terminam a execução em um período menor que lw e ficam esperando o próximo clock.
Vale lembrar que para o funcionamento correto do fluxo de dados, o program counter deve manter o endereço da instrução sendo executada até que a mesma seja concluída. Isso é necessário para que os sinais dentro do fluxo de dados fiquem estáveis, sem causar problemas de temporização, após o tempo de propagação das unidades funcionais e assim permaneçam até a próxima borda de subida do clock.
Em outras palavras, os sinais necessários para a correta execução da instrução, chamado de estado interno do processador, deve ser mantido até que a execução da instrução termine.
Para entender melhor, vamos analisar as etapas que fazem parte do fluxo de dados.
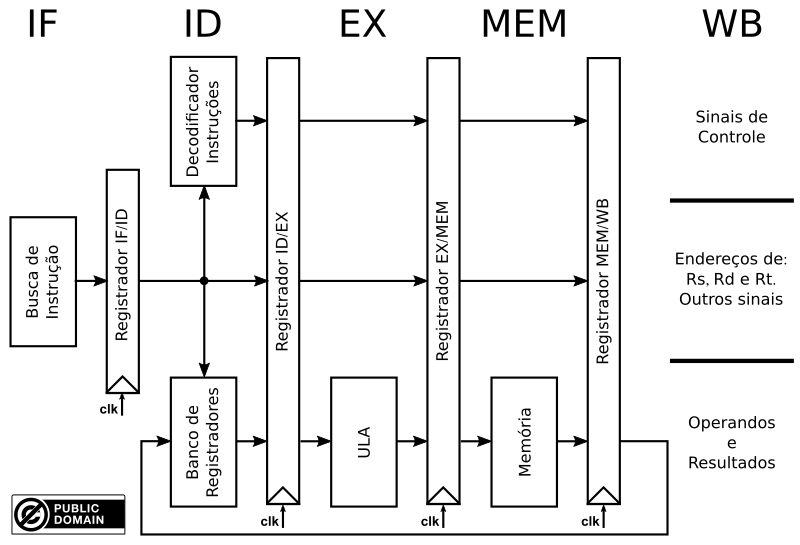
Etapas Funcionais do Fluxo de Dados
O RISC V de ciclo único pode ter seu fluxo de dados dividido em 5 etapas funcionais:
Instruction Fetch (IF): busca da próxima instrução, na memória de programa, a ser executada;
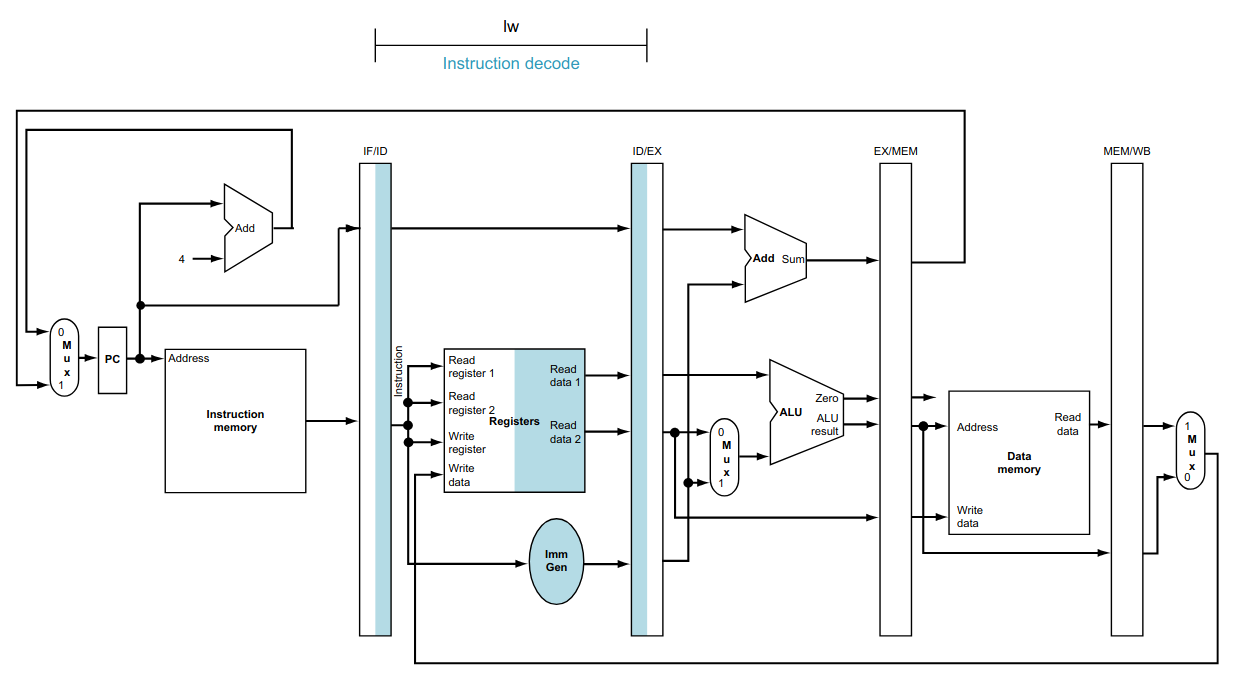
Instruction Decode (ID): decodifica a instrução (UC) e faz a leitura dos registradores utilizados pela instrução;
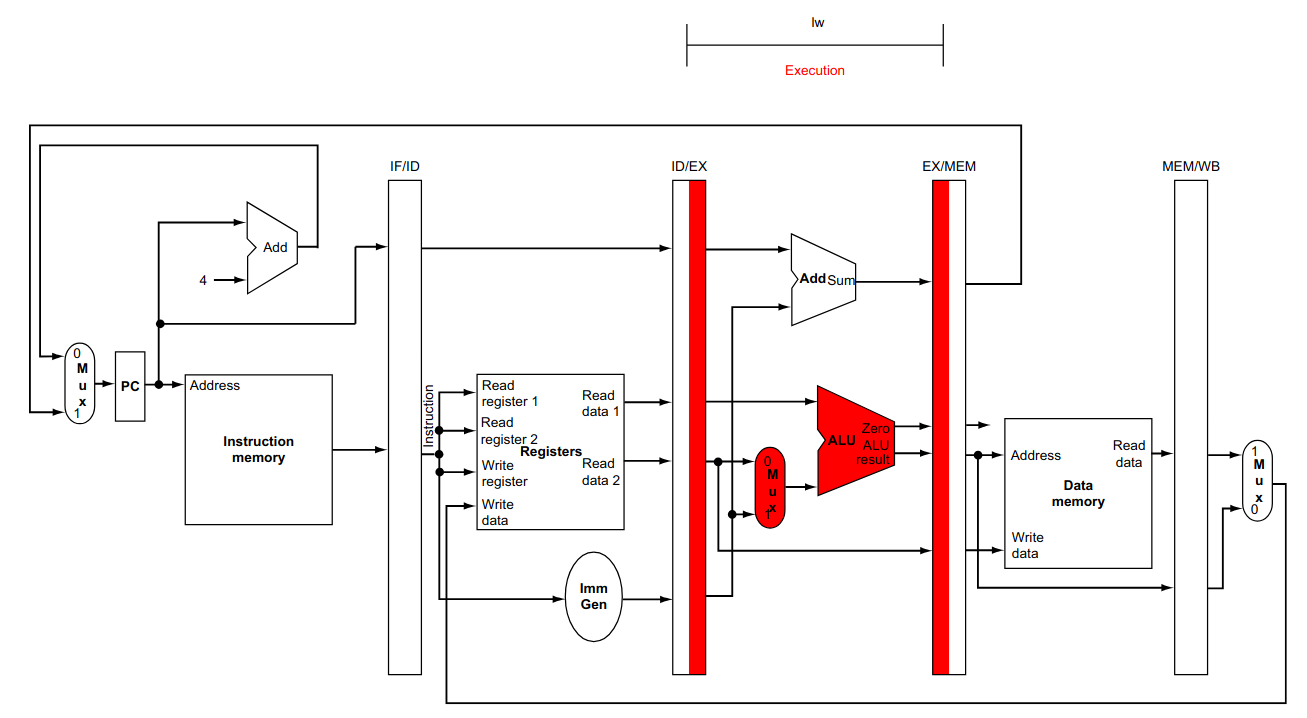
Execute (EX): executa a operação definida pela instrução. É sempre feita na ULA;
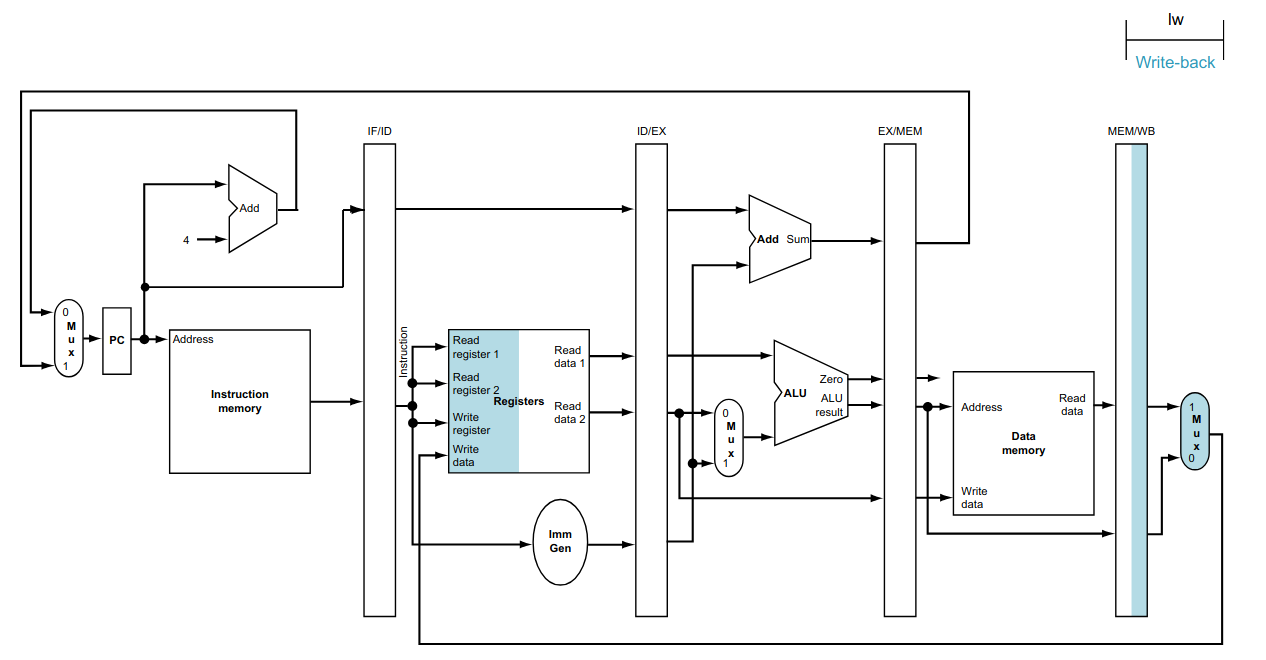
Memory Acess (MEM): lê a memória ou escreve o resultado da execução na memória RAM;
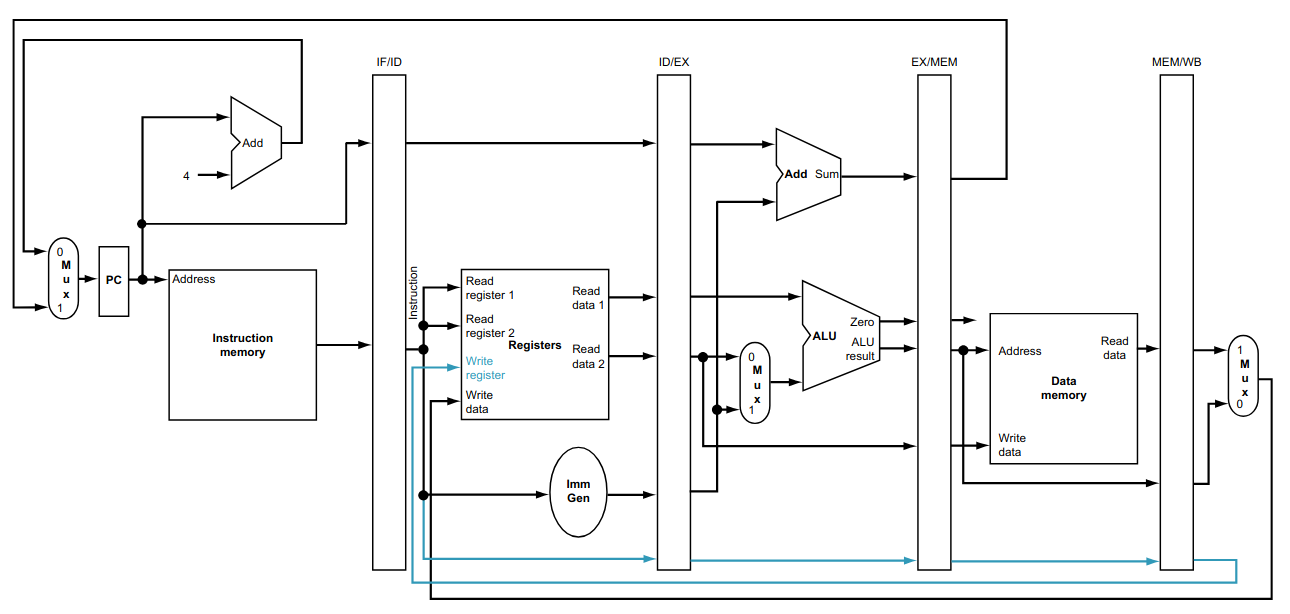
Write Back (WB): escreve o resultado da execução no banco de registradores.

Essa divisão mostra que o fluxo das instruções segue do program counter para a memória RAM, com somente duas exceções. Elas são o retorno do endereço, calculado pela instrução beq (e jal não mostrada no desenho), para atualizar program counter, e o retorno do dado a ser escrito no banco de registradores (a consequência disso será tratada em aulas posteriores).
Para simplificar a análise, consideremos que cada uma etapa dessas etapas possui o mesmo tempo de propagação (tp = 200 ps), com exceção do acesso ao banco de registradores, que utiliza 100 ps para escrita e 100 ps para leitura. Além disso, utilizaremos um diagrama simplificado para o fluxo de dados.

Nesse caso, o período do clock é de 1000 ps. Porém, se puder ser feita a separação da execução em cada etapa, poderíamos ter um período de clock de apenas 200 ps. Mas, para tanto, precisamos respeitar o estado interno para que a execução seja correta.
A solução é armazenar o estado interno de cada instrução em cada uma das etapas, fazendo com que a transferência de informação entre as etapas contenha a instrução e seu estado.
Utilizando essa divisão e isolando as etapas de execução, através de registradores que mantenham o estado necessário para a execução da instrução corrente durante aquela etapa, podemos resolver esse problema. Essa construção é conhecida como pipeline clássico e está no diagrama abaixo.
Vantagens e Execução
A grande vantagem é o ganho de desempenho. Para entender como o ganho acontece, podemos fazer a analogia com a execução de instruções em fluxos de dados diferentes e em paralelo.
O diagrama, abaixo, mostra a execução de 3 instruções lw em um fluxo de dados de ciclo único. Note que o indicado no fluxo de dados é o recurso sendo utilizado naquele período de clock.
Para a execução das 3 instruções teremos um tempo total de 15 clocks de 200 ps, ou seja, 3.000 ps.

Se executar-mos essa mesma sequência de instruções em um pipeline de 5 estágios, teremos um total de 1.400 ps, ou seja, 2,14 vezes mais rápido.

Como o pipeline possui 5 estágios e usamos somente 3 instruções, o ganho de desempenho não foi o maior possível. Porém, como o pipeline “cheio” e sendo alimentado continuamente por novas instruções, teremos um ganho maior (por volta de 5 vezes mais rápido). A tabela abaixo mostra essa situação.
| Instrução | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EX | MEM | WB | |||
| 2 | IF | ID | EX | MEM | WB | |||
| 3 | IF | ID | EX | MEM | WB | |||
| 4 | IF | ID | EX | MEM | ||||
| 5 | IF | ID | EX | |||||
| 6 | IF | ID | ||||||
| 7 | IF | |||||||
| clk | 1 | 2 | 3 | 4 | 5 | 6 | 7 |